


How I Built a BI Platform from Scratch without committing suicide ! (Part 2)
Part 2 - The Backend


Hooooo! IT! ☺
It's moving at a breakneck pace! It used to be that the choice of technology (Programming language) was paramount before starting a project. It (the techno) determined what you could and couldn't do and the limitations.
I'm not saying that this is not the case anymore, but this big barrier between the technos doesn't exist anymore. Nowadays, whether it's Java, Python, JS/TS, or even PHP, they're all capable of building a very high-performance, high-load application.
Javascript has always been my favorite. But during this project I was amazed at the power of this technology that we tend to underestimate. JS has been able to evolve very quickly while keeping its charming simplicity that allows everyone to embrace its universe without any headache.
Its mutation, Typescript, allows us to explode our limits and to place it in the restricted circle of mature languages such as Java. I don't make a confrontation between Java and JS but it's a fact that this language competes with compiled technos and continues to be just as powerful and elegant.
While doing my research on the problem of connecting to multiple databases, I tested several technologies for a Proof of Concept.
JAVA was way too boring with its very large functions to do small things. DotNet was very cool but required more resources and to expand the team would cost more. PHP I was a bit fed up with and the setup to solve this problem was too painful. Then I said to myself: "good let's see with NodeJS".
NodeJS is the most wonderful thing that happened to JS. It has allowed JS to reach the top and conquer the world. But it is too open in its implementations and standards which leaves it up to each developer to do what he wants as he wants.
So I needed a Java-like organization that would take all the advantages of Angular.
And then like a revelation I remembered that I knew a similar thing and its name is : NEST JS**. 🔥🚀
NESTJS THE SAVIOR!

My choice from the POC was a no-brainer. This techno had all the advantages of Angular and allowed all those who had previously suffered with Express to discover the benefits of evolution and to focus on the most important while the Framework took care of the rest.
I won't list all the things you need to know about NestJs but I recommend you this article which talks about it in more details in addition to its Official Documentation which is one of the best in the WORLD:
https://codeburst.io/why-you-should-use-nestjs-for-your-next-project-6a0f6c993be
CONNECTING TO THE DATABASES
As announced several times the company has data stored for more than 17 years in different servers and different databases of different types.
If I had wanted to create entities & relations for each database of each system I would have taken a year to finish everything without taking into account the errors and the risk of deleting everything in a table because of a bad manipulation.
I had to get out of the box, be ingenious on the method. I had the technology, I had the needs but how to extract the data 🤔.
It's obvious that I needed Database First! But the only technology that was really comfortable with that was .Net C# and I wanted that with Nest. So I got to work.
First the connection to the bases progressively according to those which interests me first:
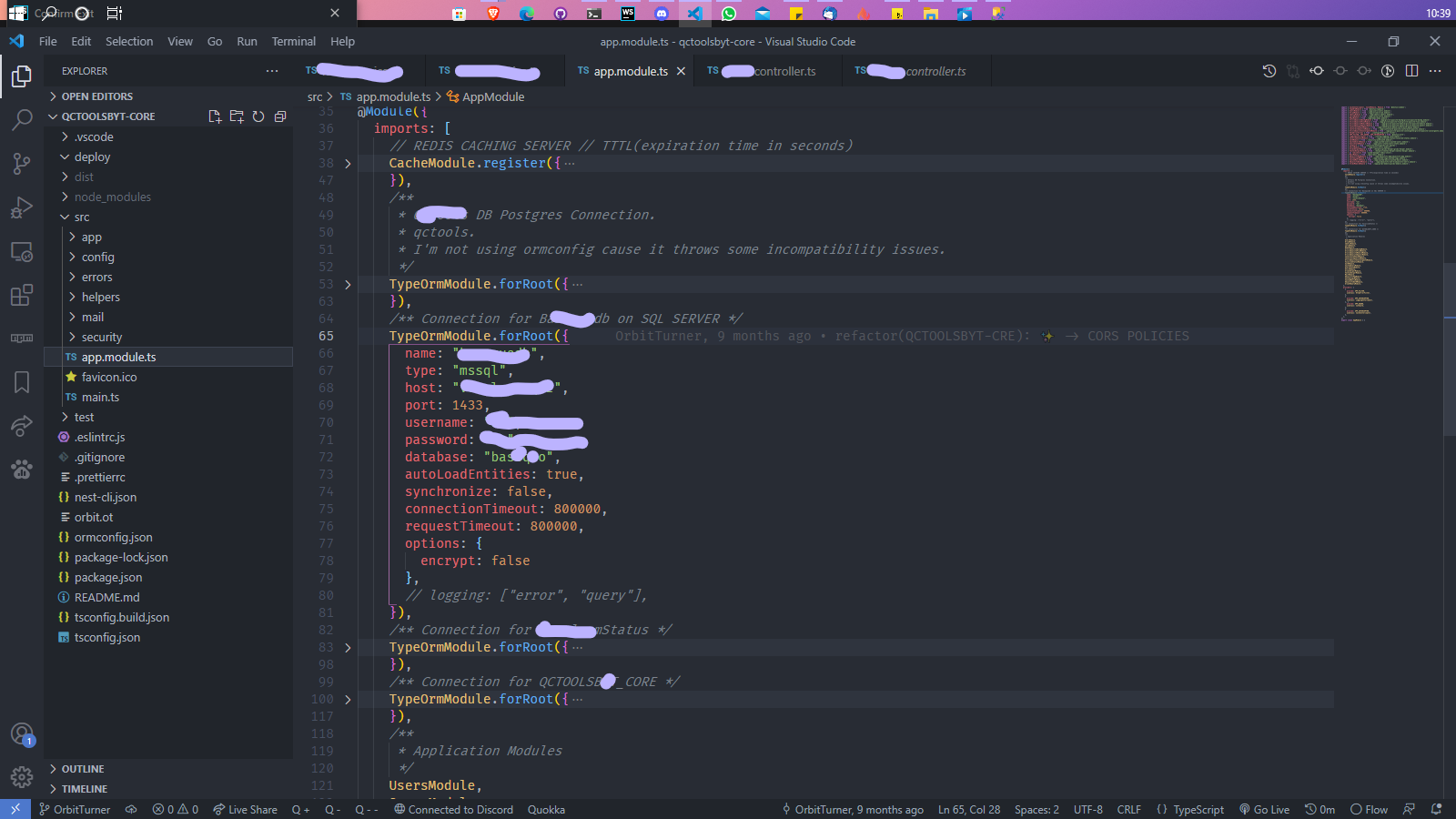
Since I had chosen TypeOrm as the ORM, all I had to do was to define each connection in the AppModule (as above) and give the information to connect to a database. Knowing also that this can be done dynamically.
Then I only had to specify in the modules the DB(s) to use:
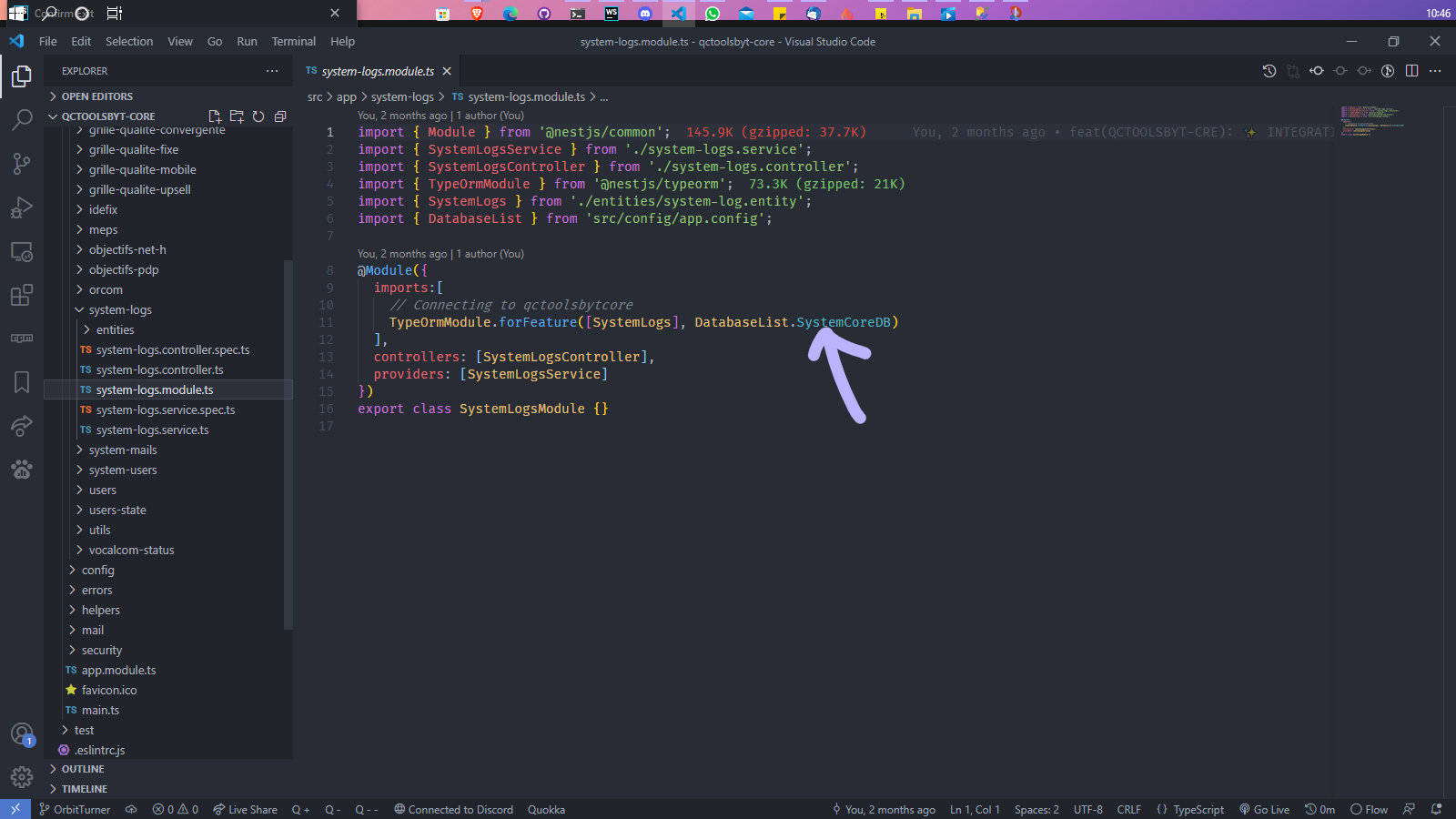
I was already feeling invincible! 🚀🔥

However, there was still another problem.
How to now easily query or manipulate all this data without having to write all the Handlers in my Controllers and all the methods in my services ?
GraphQL maybe? 🤔
In this case also how to foresee all possible questions or filters without writing all resolvers?
😂 Yes I am really very very LAZY 😂 I am ALWAYS looking for shortcuts.
I remember at that time one of my buddies told me "Bro you know you always want to do the impossible, but this time what you ask even Google doesn't have the answer" 😂😂😂😂.
Basically I wanted to have a REST API but that would behave like GraphQL, that is to say that in the GET requests I could filter on the fly the data I was going to get from the database. So the GET request will indirectly build the SQL request.

The why?! Because said like that it seems strange but the impact is enormous in the system if directly in front I am able to ask questions like: Which are the active users whose log begins with F, who are between 30 and 40 years old and are of Senegalese nationality ? and that I don't have to anticipate this in the backend with methods in Controllers and Services, I would have an incredibly flexible and lightweight system.
What about all those CRUDs to do for hundreds of tables and an array of databases?
I had to find a way to automate that and deal with that redundancy problem from the start.
That's when, in the middle of all this chaos, after days and days of searching, I stumbled upon a microframework for NestJS that says: "@nestjsx/crud".

I wasn't dreaming! This stuff really existed and yet not many people knew about it 😭😭
NESTJSX/CRUD
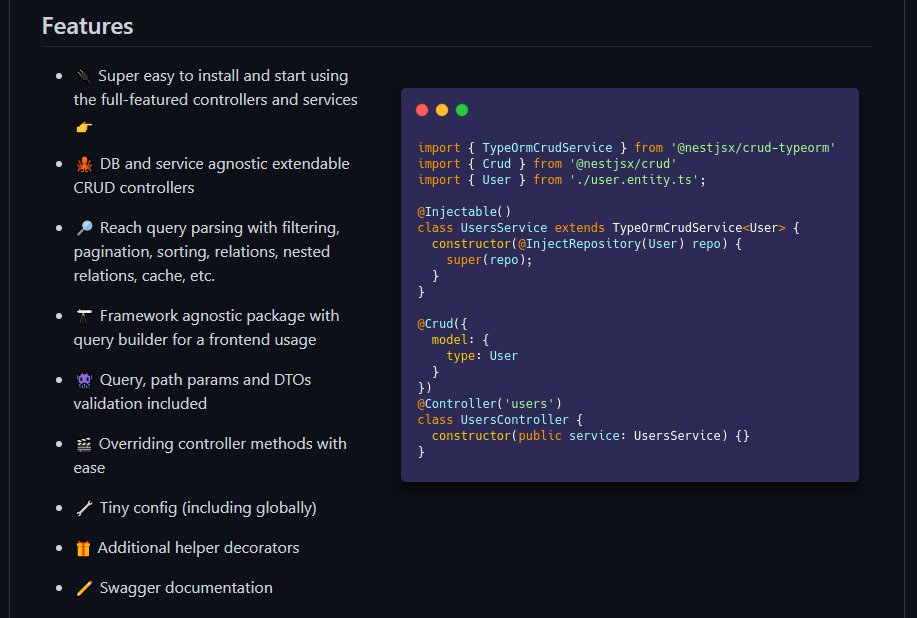
This trick allowed me to have, as in the code on the right above, full CRUDs, the ability to Filter, Paginate, Relate and Sort the information I needed during retrieval even in base with hypersafe optimized queries (read more)!
For example here is the query for the question I asked about users above:
Which are the active Users who have an age between 30 and 40 years and are of Senegalese nationality?
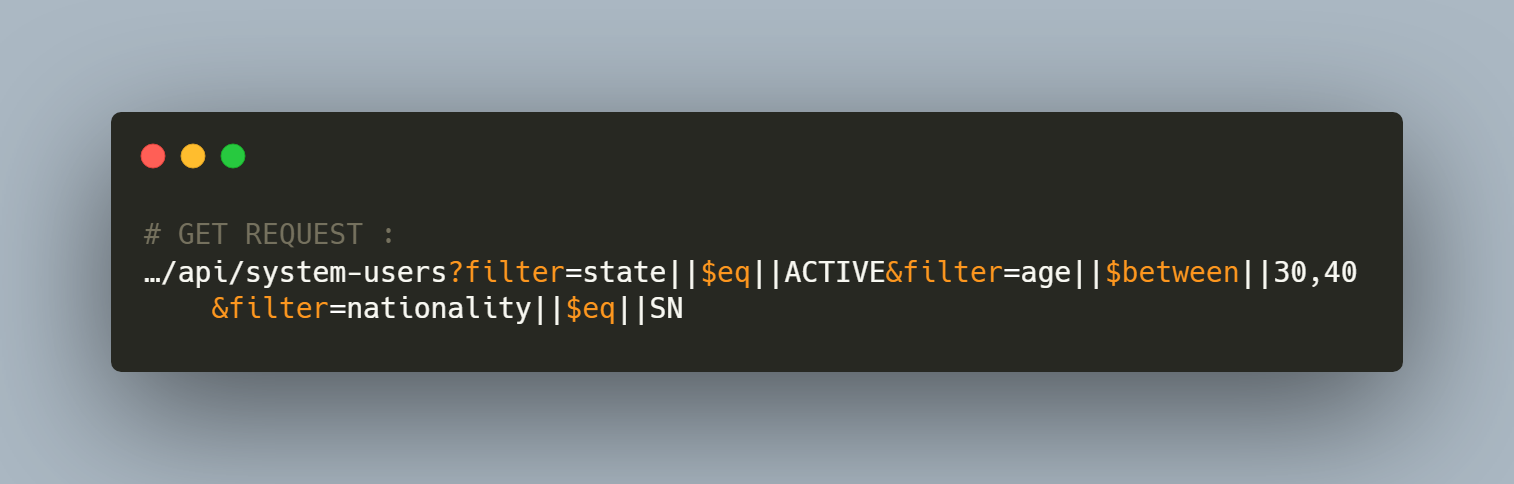
In reality the SQL is built according to the request (logical you will say but boff do a tour on their doc you will understand what I mean).
In the code the implementation is just as simple. For example to have the endpoints below and their Swagger documentation:
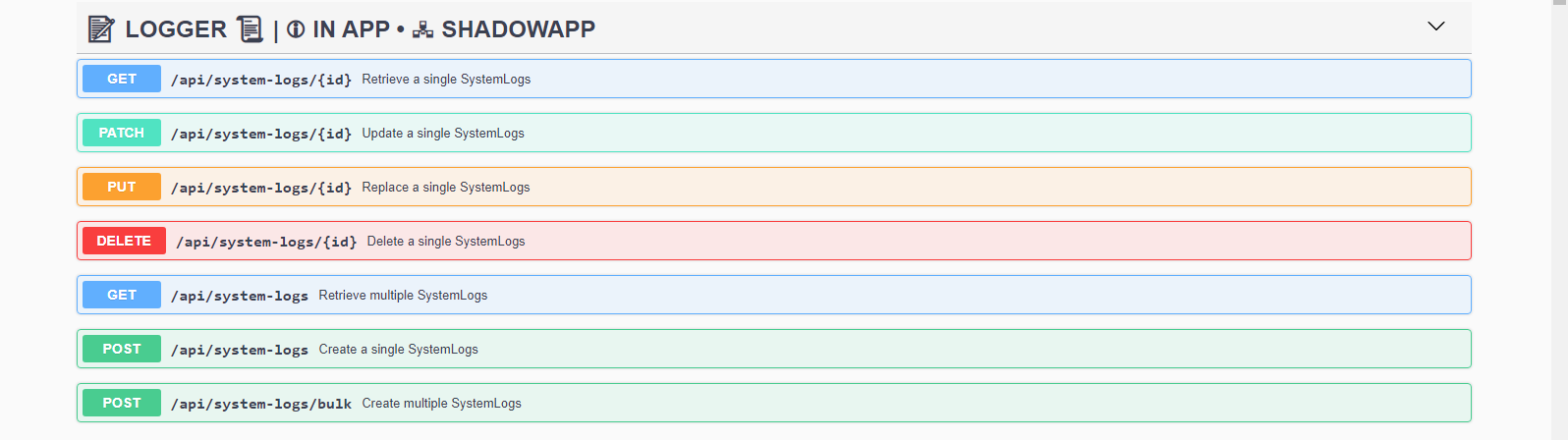
We will have in the controller :
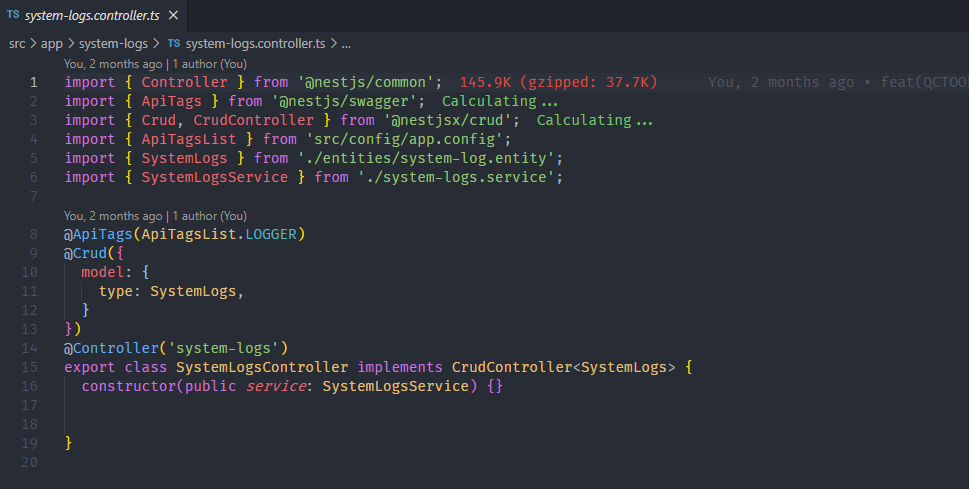
And in the service :
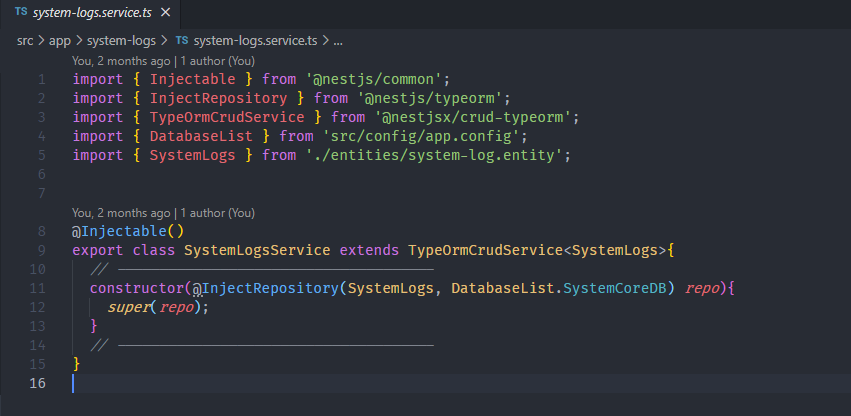
That's All! 😂
In the case where, as in 60% of the time, we need more specific processing, we will only have to make an Override of the existing methods or create new ones as in any other app.
Example:
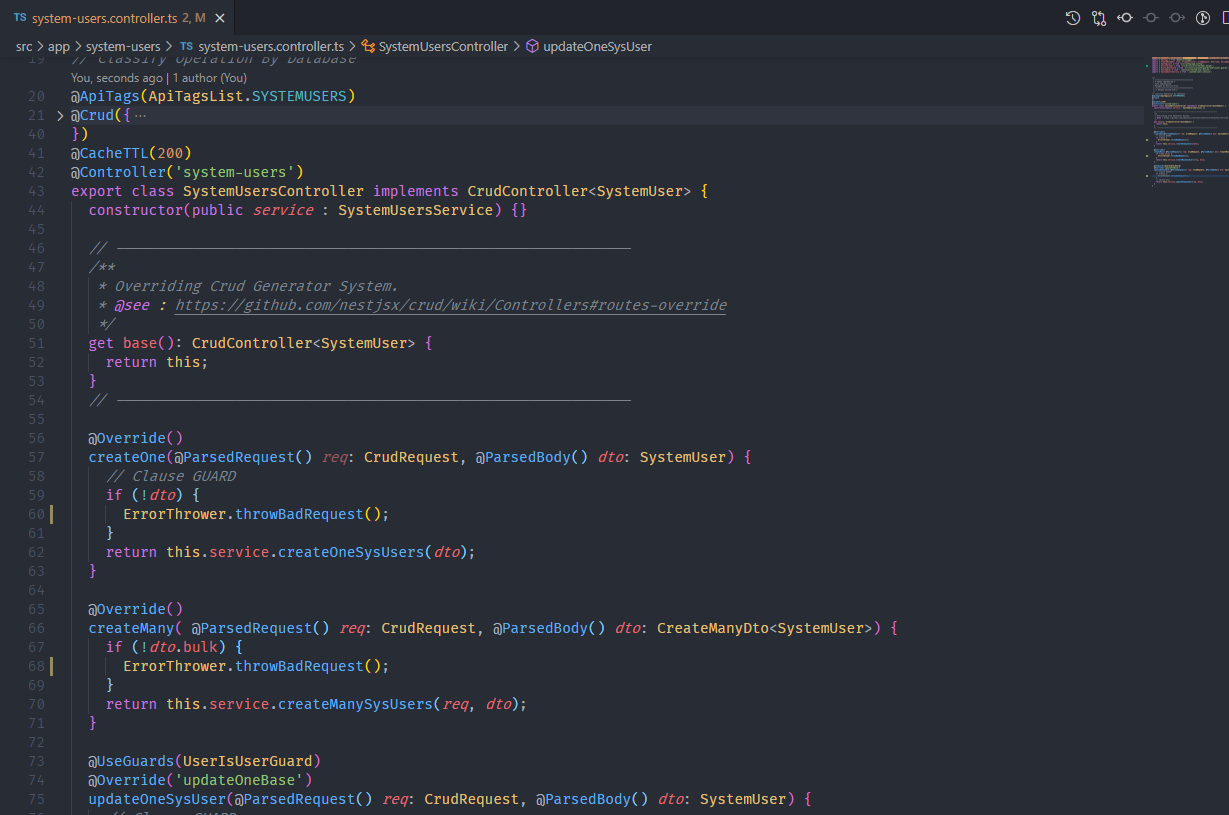
So I was able to do a lot more in a short time.
I'm such a fan of this library that I ended up contributing code to it on GitHub to add new features.
But I still had the issue of entities 😭.
ENTITIES GENERATION
As I said earlier even if I could specify in the configuration of each DB that the app can't overwrite the base, I couldn't accept to spend my time making entities for TypeORM and put months to make relations here and there.
So now you know the song as the credits roll: *Orbit takes a shortcut and Orbit generates!
The next Hero is an npm package: *typeorm-model-generator*.
As its name indicates it allows to generate directly TypeOrm entities based on the given base.
With a line like this one :
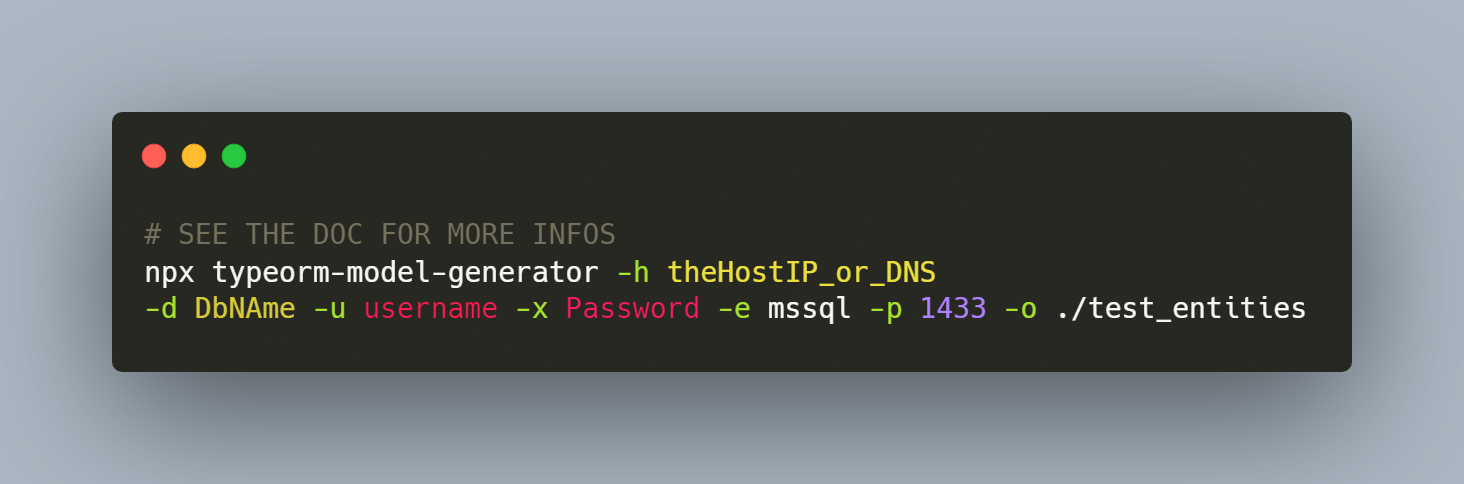

I could generate entities for all tables in the specified database with relations and everything!
This solid base and well optimized to go fast allowed to establish the project well and to start with only two months of the starting to chain the deliveries.
NESTJS ARCHITECTURE
The hierarchy on the back side is very similar to the front side with a helpers oriented methodology that allows to share the processing between several modules and to facilitate the reuse and the evolution.
At the beginning I had thought each module as a microservice deployed separately but I realized that I was in Over-Engineering with respect to the context and that the performance gains were very debatable.
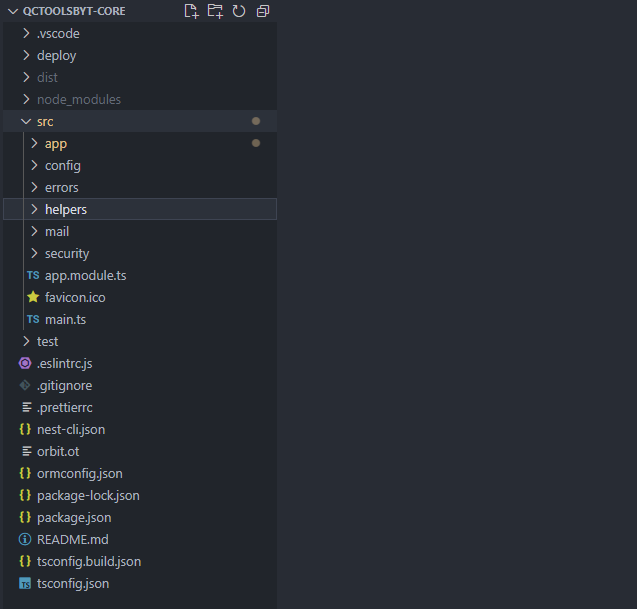
Then I kept this same ideology that I implemented in the same backend since Nest had a very modular design that allows you to have several independent blocks in your application.
ETL PROCESS
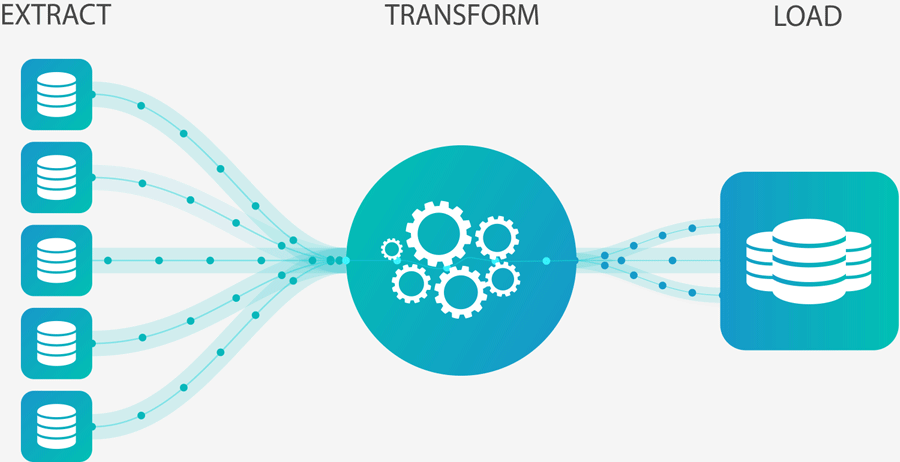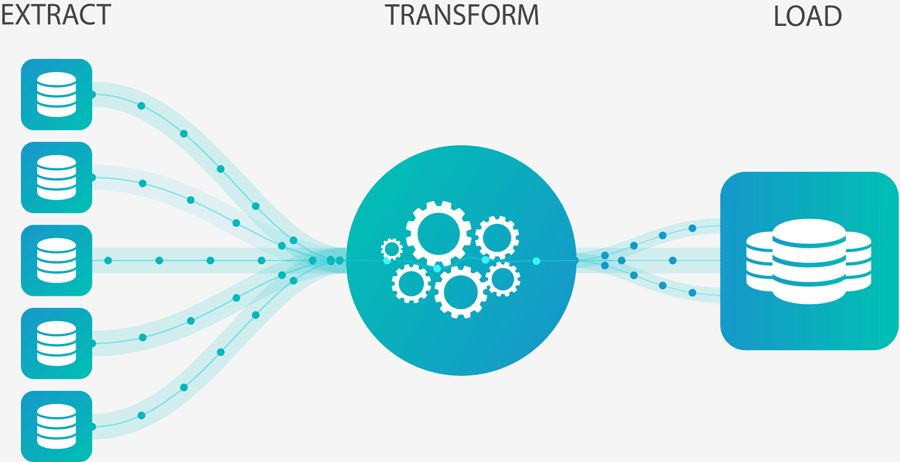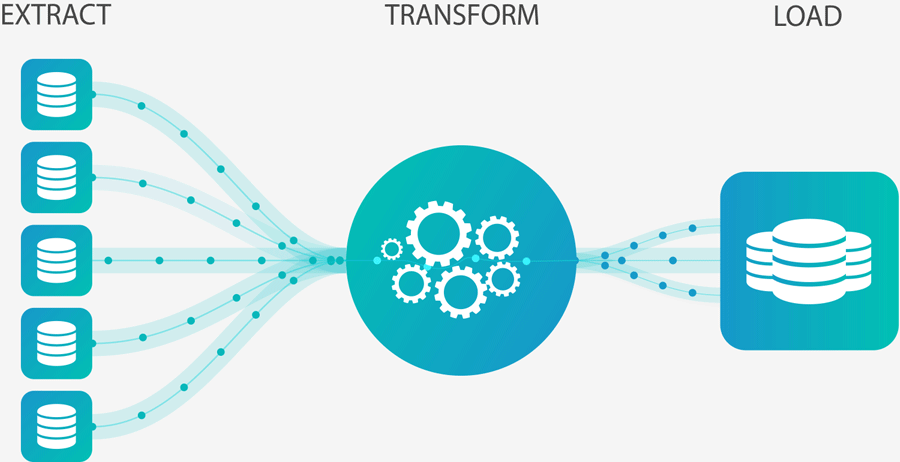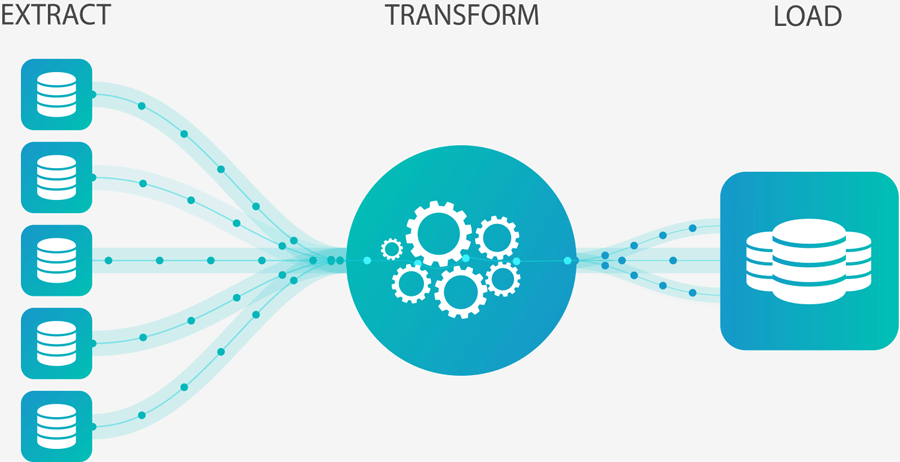
You can imagine that when we talk about BI, we will inevitably talk about ETL.
According to the internet definition, it is an automated process that takes raw data, extracts the information needed for analysis, transforms it into a format that can meet business needs and loads it into a data warehouse. ETL typically summarizes data to reduce its size and improve its performance for specific types of analysis.
In our case the 'Load' phase will be more associated with 'Visualize' because even though sometimes the processed data is put into Warehouses.
The well managed Backend structure allows us to focus on the algorithms and processes to be implemented in order to exploit these large masses of data.
It is important to know that usually for a "normal" application as we are used to do for small customers many things are ignored on the code side. Such as the time to call the DB, the timing of loops, their types, as well as the performance in time and resources of a function, a helper or a Microservice.
On the other hand, under the weight of all this data, the smallest optimization is exponential on a whole module.
We have spent several hours benchmarking between a FOR normal loop (for i ...) and a FOR OF loop. Several hours testing several methods to iterate on arrays. Several days implementing different search, sort or graph algorithms and measuring their performance.
Several weeks to set up our own implementations or ORM overlay because sometimes some needs are so specific that no ORM could foresee that so we have to create our own solutions and optimize them.
Example of a Utility Service allowing to manage Transactions, Prepared Queries, Views, etc. on SQL SERVER databases. 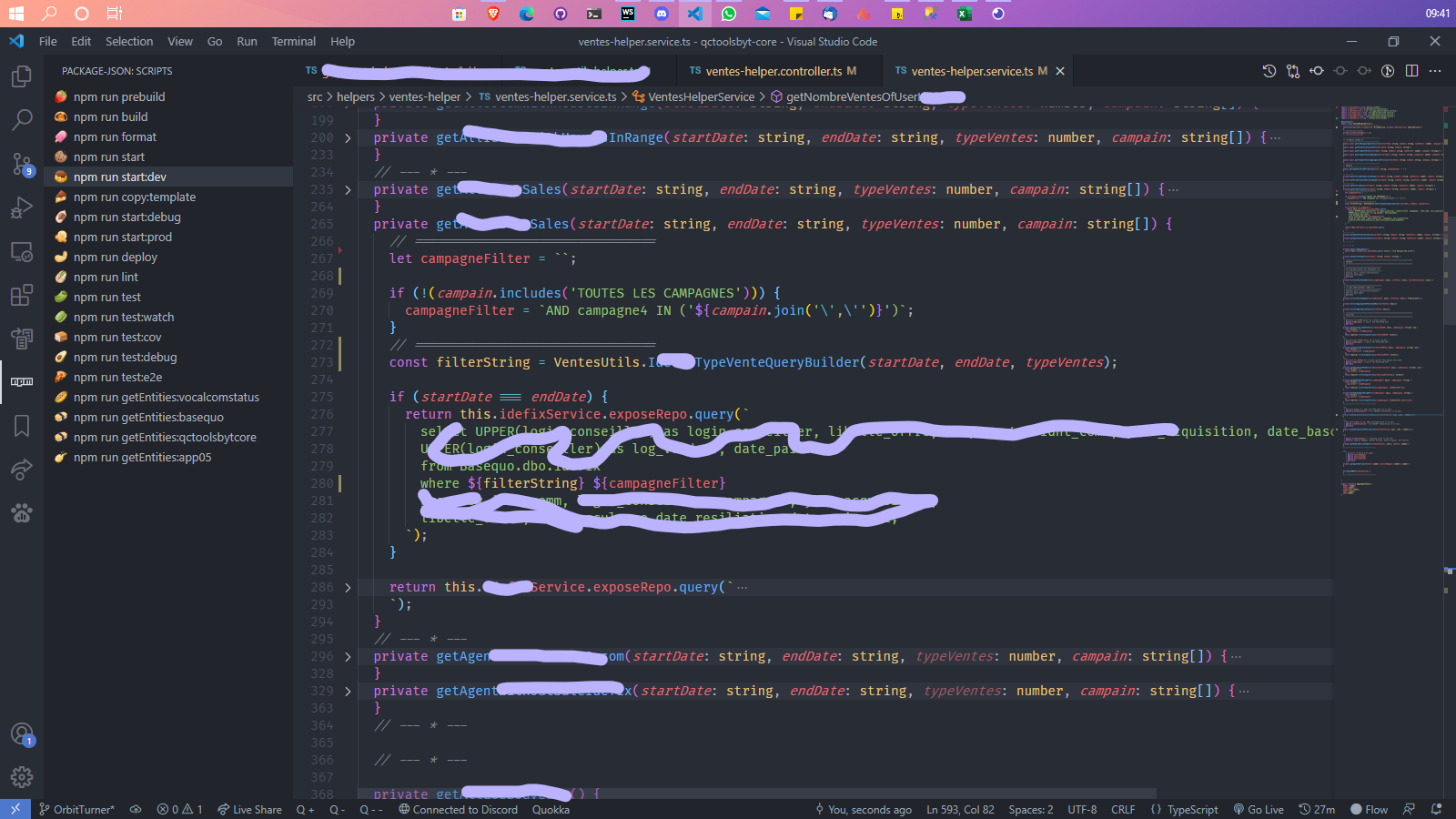
The obtained data are often transmitted to the frontend in the form of statistics so that the DataViz components can generate Charts and Graphs.
Some modules that are very complicated in logic or in implementation take us a lot of time to plan and little time to implement.
Let's take as an example one of our extraction/compilation modules that allows from the front-end to choose several data sources and compile them in a single table with a dynamic crossing between the chosen sources.
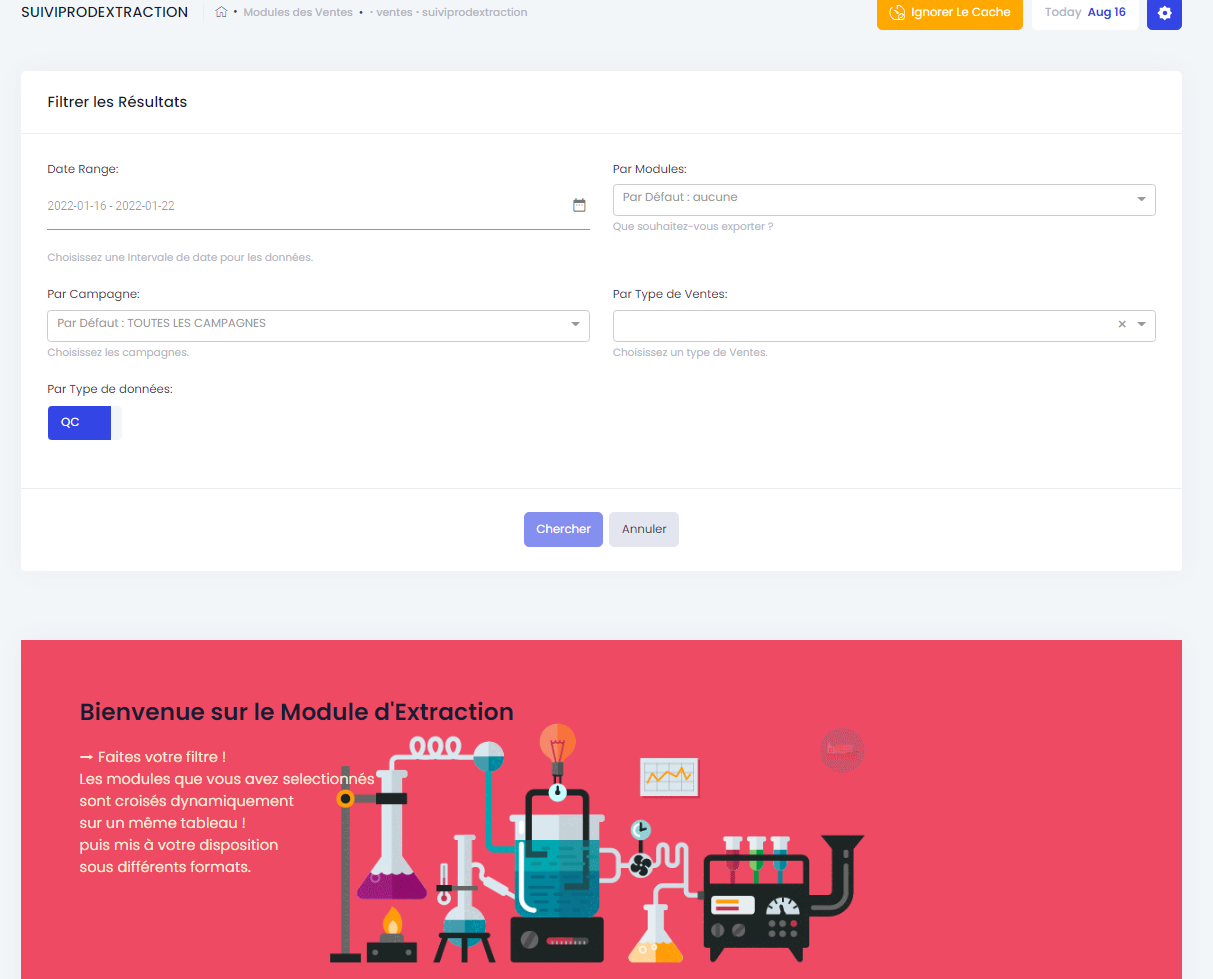
Once the filters have been applied, it offers us to extract (download) them in different formats:
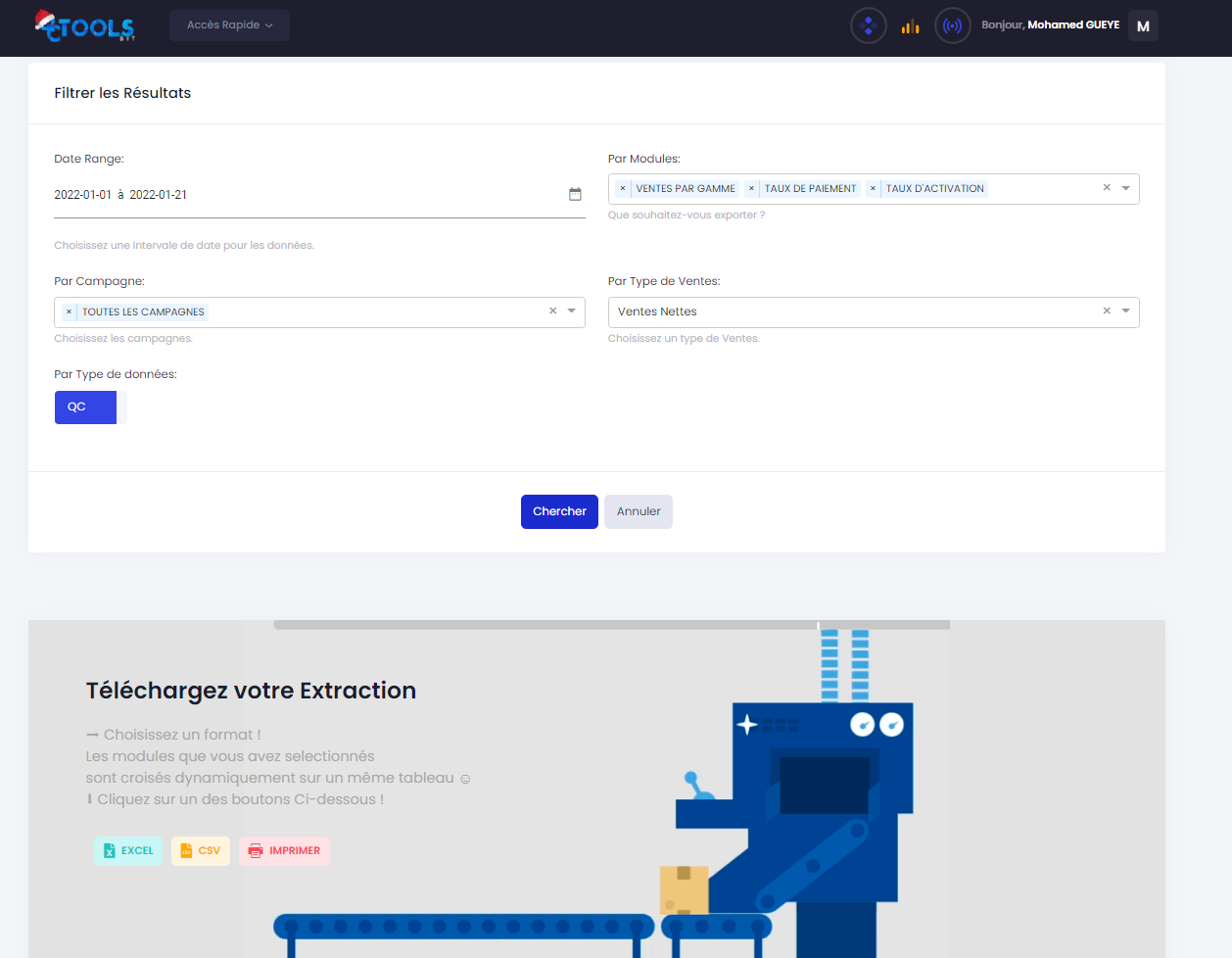
As complex as it is we have it as follows in the Backend:
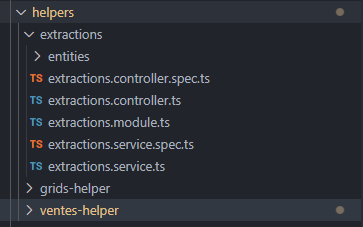
Above we have the extraction module in the backend which is among other modules of type helpers.
Then we have in 'extractions.entities.ts' the different interfaces and/or types that define the manipulated and rendered objects.
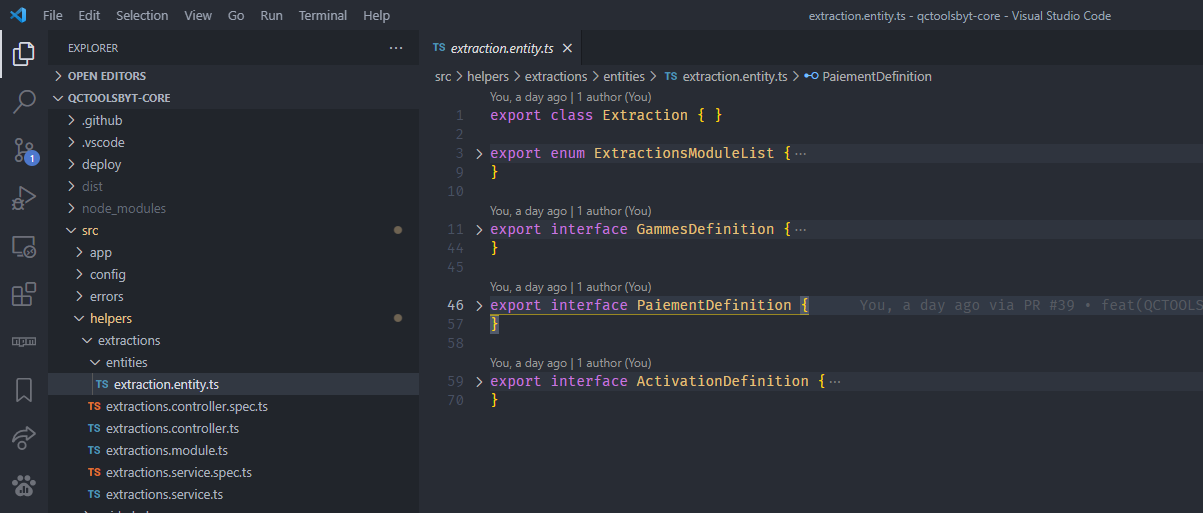
In the controller we find successively the swagger documentation, the route definition, the validity time of the REDIS Cache and finally a call to the service responsible for the processing. (The routes have been deleted for better visibility)
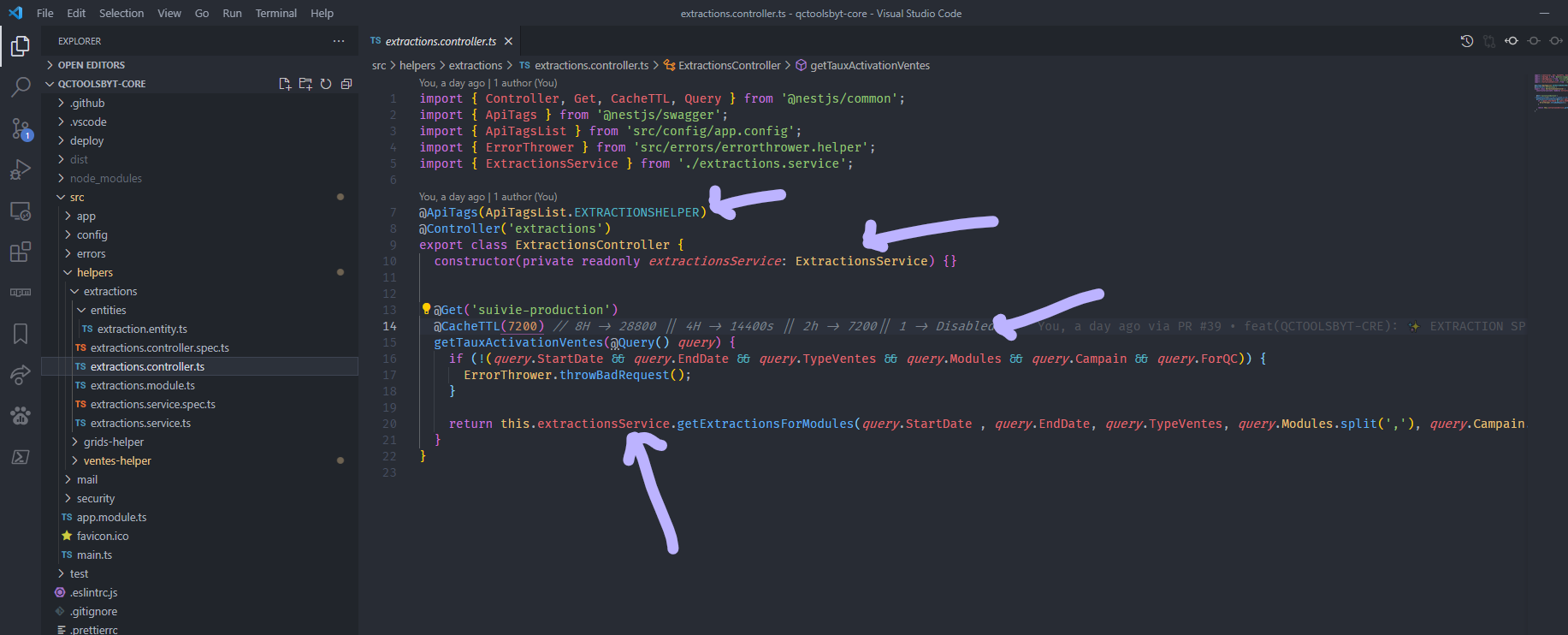
In the module definition file we have the different dependencies to the other modules we will need. As explained earlier, we have to see these modules as lego blocks that can be put into other applications or transformed into microservices without any problem.
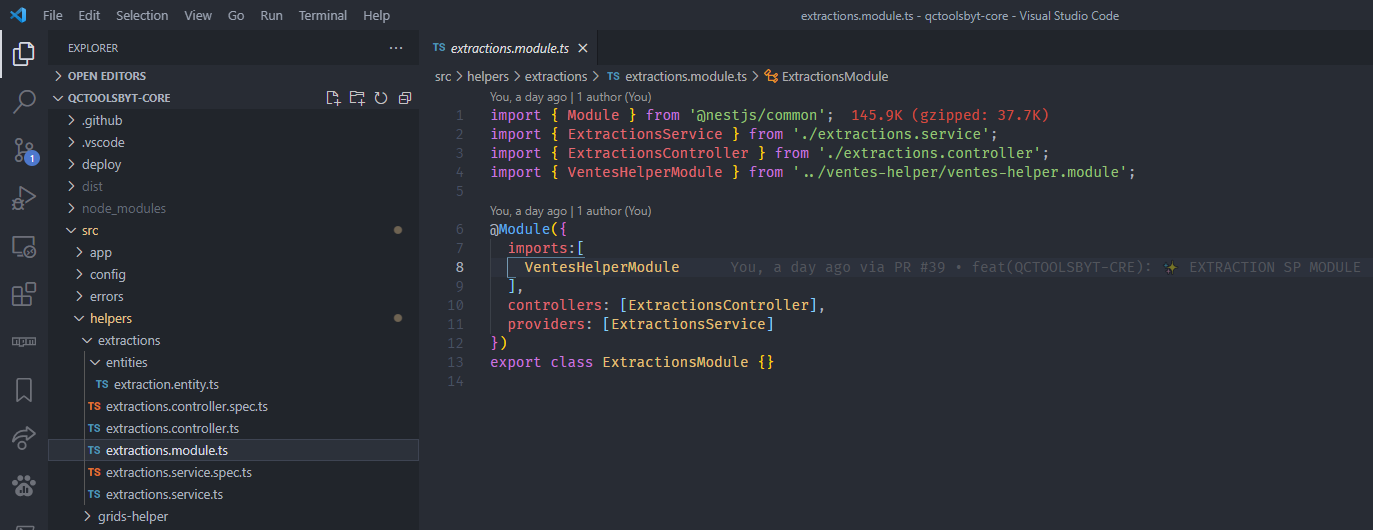
In the service, which represents the worker of this module, we find all the functions/methods allowing to carry out the treatment(s).
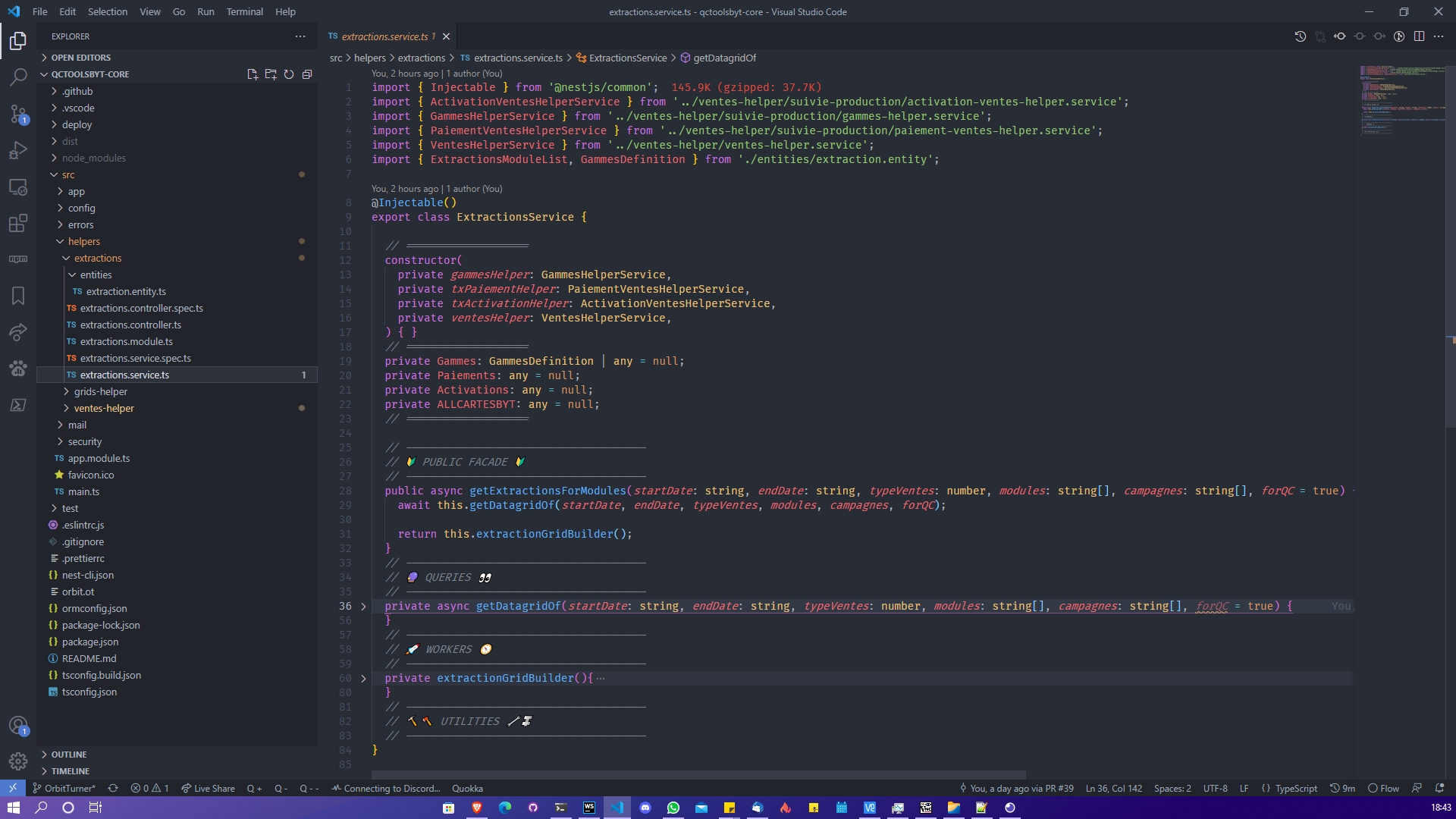
First we have the "PUBLIC FACADE" of this class which represents the entry point of the service. It is this class that all the other modules will call when they need its help.

Then we have the "Querier" they are in charge of gathering the data we need to do the processing. Here they are quite special because they have to make a request only if their module is selected. Note the parallelization of the processes with the "Promises" we will come back to this later.
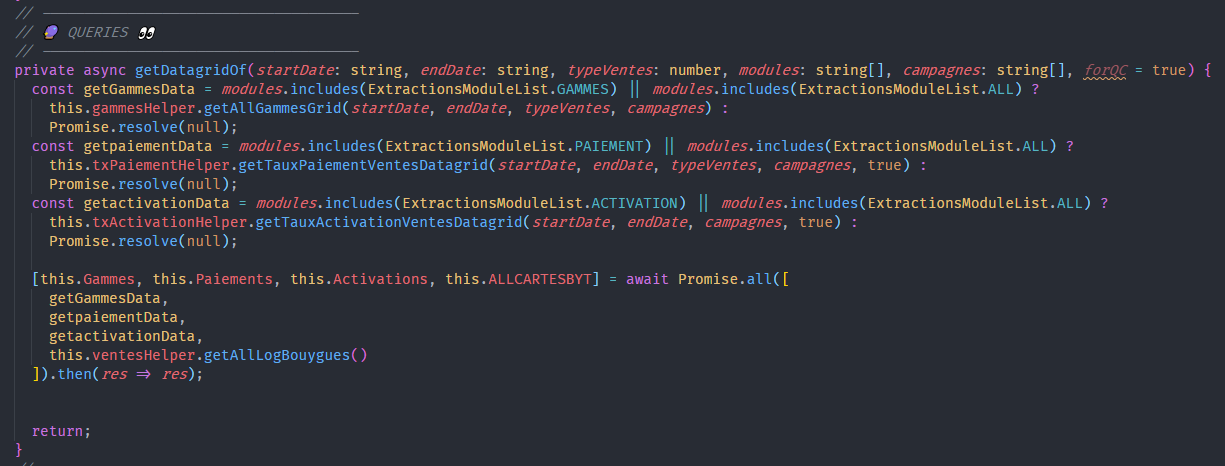
Finally we have the "WORKERS". This is the function(s) or method(s) that do the hardest part, i.e. the logic and assembly of all the intermediate products.
This is where the notions of Optimization, data structure and algorithmic come into play most of the time. It will be one of the key elements of the accuracy, speed and performance of a processing.
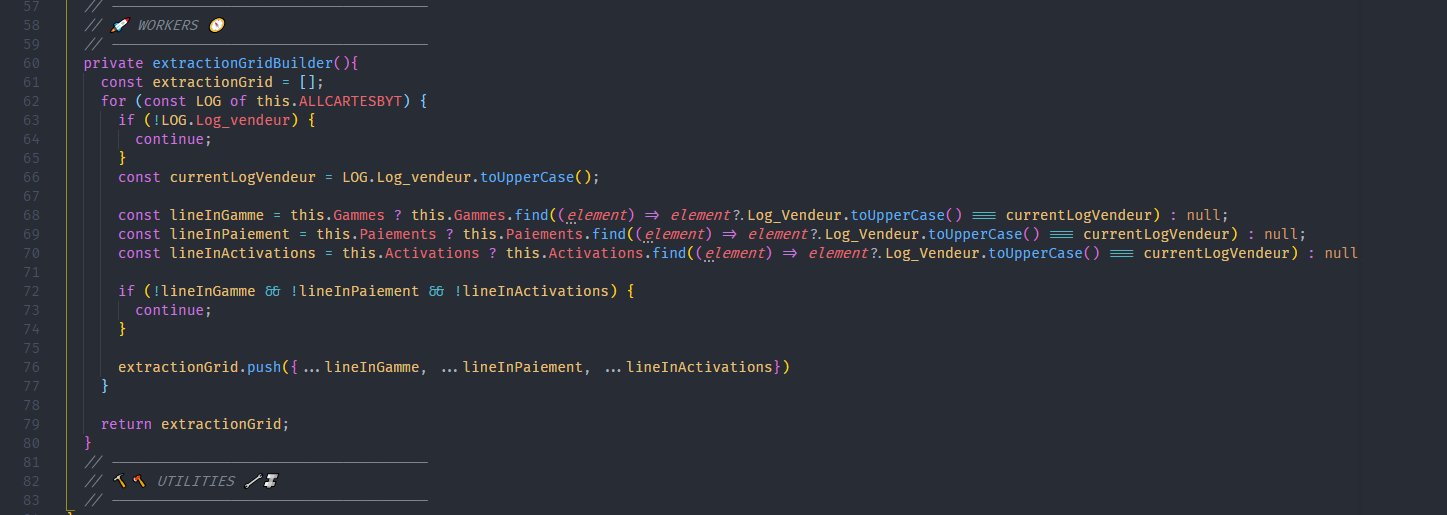
It is often accompanied by utilities in order to always stay in the solid standards and to facilitate the readability of the code.
Each module makes its treatment by applying almost this approach but obviously the logic and needs in each of them.
PREDICTION & FORECASTING AI (TENSORFLOW JS)
Machine Learning and DataScience with ... JavaScript 😨?! Yes, it is possible🥳. Python is not the only language you can use to do this.
**Tensorflow has a JS version that allows you to appropriate ML or DS with JS. I'm just starting with Tensorflow so this "*Prediction*'" part is currently handled from the Power bi API. But we are moving more and more to [Hal9](hal9.com) **based on TF which will allow us to easily have multiple access to prediction just with their APIs:

...
Once all this was set up, the other challenges were to always succeed in meeting the various demands in terms of Dashboard, metrics, features while keeping the application always faster and more available.
We will now tackle the last part. The one that represents a new challenge with each new feature.
**Optimization and Scaling !

Follow me on socials :
https://liinks.co/orbitturner 🚀 ORBIT WORLD ⍟ Keep Going Further 🚀 What does it look like working with me or futurize? Discuss the project The customer at the center of the project! I...orbitturner.com